Data Encoding
When sending data over the wire or storing it in a disk, we need a
way to encode the data into bytes. There are different ways to do this:
1. Use programming language specific serialization
such as Java serialization or Python's pickle, which makes developers in other
languages frown.
2. Use language agnostic formats
such as XML or JSON, and we are particularly excited by JSON's simplicity. XML is too old school.
However unlike XML which has xml schema, JSON is not a strictly defined
format, even with JSON schema, which has a few drawbacks to make you bite your nails . First, it doesn’t
differentiate integers from floating point, second, they are still verbose because field
names and type information have to be explicitly represented in the
serialized format. Lastly, the lack of documentation and structure makes consuming data
in these formats more challenging because fields can be arbitrarily
added or removed.
Updated: JSON Schema defines seven primitive types for JSON values:
- array
- A JSON array.
- boolean
- A JSON boolean.
- integer
- A JSON number without a fraction or exponent part.
- number
- Any JSON number. Number includes integer.
- null
- The JSON null value.
- object
- A JSON object.
- string
- A JSON string.
3. Using binary format.
One of the IBM mainframe i-series AS400/
RPG uses the a binary data for
record-based columnar like format, with predefined data type size and record size. But it
may waste lots of space since every field and record has different
sizes.
For example: [3, 27] is an JSON array containing the items 3 and 27, it could be encoded
as the long value 2 (encoded as hex 04) followed by long
values 3 and 27 (encoded as hex
06 36)
terminated by zero:
04 06 36 00.
4. To describe all of the bytes in the above binary format, we need
a document and contract between producer and consumer, or schema. Here
comes the libraries include
Thrift ,
Protocol Buffer and
Avro.
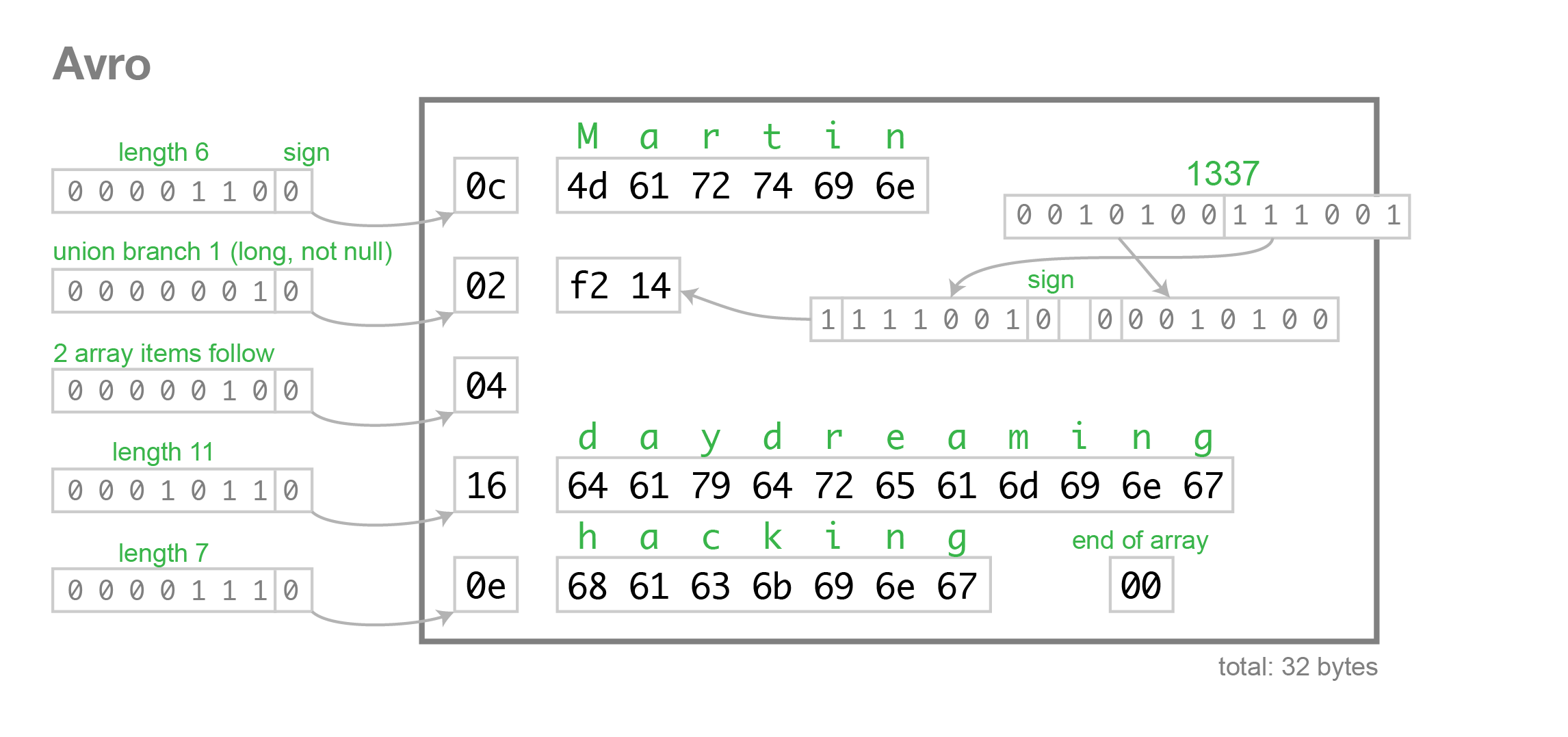
The below diagram illustrates the bytes encoding using Avro format.
Source:
avro.png
Schema plays pivotal role here and is required during both data serialization but also data
deserialization. Because the schema is provided at decoding time,
metadata such as the field names don’t have to be explicitly encoded
in the data. This makes the binary encoding of Avro data very compact.
Another benefit Avro schema brings is that for static type languages like Java, the serialization and deserialization code can be auto-generated from the schema.
Schema Evolution
One thing is never changed in software development is CHANGE itself, in this case, the schema changes.
Schema evolution is defined as how
the application should behave when Avro schema is changed after data has
been written to the store using the older versions.
Schema evolution is about data transformation. Avro specification itself has detailed information about how the data is handled when downstream (reader) schema is different from the upstream (writer) schema. When that happens, the data transformation from one schema to the other is performed.
Schema evolution is applied only during deserialization.
If the reader schema is different from the value's writer
schema, then the value is automatically modified during
deserialization to conform to the reader schema. To do
this, default values are used.
There are three common aspects of schema evolution:
backward
compatibility, forward compatibility, and full compatibility.
Let's consider two cases: add a field and remove a field.
To add a field, in order to support schema evolution, a default must be defined.
{"name" : "gender", "type" : "string" , "default" : "null"}]
When reader using old schema encounters this new field, the transformation will automatically drop this new field, this is called forward compatibility.
When reader using new schema encounters data without this new field, the transformation will automatically add this new field and set its value to null. This is called backward compatibility.
The same thing applies to remove case, which I leave it as an exercise to the readers.
Enum evolution
The intriguing part about schema evolution is the Enum evolution. The following line is from Avro specification:
- if the writer's symbol is not present in the reader's
enum, then an error is signalled.
This makes schema evolution for enum impossible, because we often need to add new values to the Enum field. And this turns out to be a long-term issue on Avro JIRA board: https://issues.apache.org/jira/browse/AVRO-1340. The proposal is actually simple:
"Use the default
option to refer to one of enum values so that when a old reader
encounters a enum ordinal it does not recognize, it can default to the
optional schema provided one."
Basically always define a default value for enum like below:
{"type":"enum", "name":"color", "symbols":["UNKNOWN","RED", "GREEN",
"BLUE"], "default": "UNKNOWN" }
Lost in translation
One interesting side effect from schema evolution is shown as below example:
Say we have two versions of schema: v1, v2, v2 has the new field called 'color' with default value of 'UNKNOWN'.
A v2 writer created a doc with color = RED.
A v1 reader parse this data, color field is removed and update the data store.
A v2 reader parse this data, color field is restored with value to 'UNKNOWN'!
Avro naming convention
Record, enums and fixed are named types. The name portion of a fullname, record field names, and
enum symbols must:
- start with [A-Za-z_]
- subsequently contain only [A-Za-z0-9_]
The reason here is because when code-generation tool generates the
code from schema, record and enum becomes the variable names. And in most of
languages including Java, variable names can not have dash.
A Case Study
Armed with the above knowledge, let's do a case study. Saying we have a data store consists of
Apache Gora and
Kafka schema registry, allows us to store data set and register schema to support schema evolution, and data store will send out any new or updated data set to Kafka pipe which allows downstream consumers to consume the dataset. Team A works on app a, which collects data and deposit it to data store, team B works on app b, which will listen to the pipe and fetch the data from data store and transform it and put in back to data store, the team A's app a also need to read this data back and make any change and put it back again. However Team B's changes should be preserved as much as we can since it is more a downstream application in this pipeline.
Approach 1:
App A with its own schema a, app B with its own schema b.
At the beginning, App A has reader/writer for schema a.1, b.1, App B has reader/writer for schema a.1 and b.1.
Considering this case, Team B add new fields to its schema b.1, update schema to b.2 and update its reader/writer to b.2. app A will read this data with reader/writer for b.1, the new field is dropped, write it to a.1, app B read updated data from a.1 now without this new fields to b.2, app B either won't be able to write this data back to b.2 or has to write a data transformation logic by itself to set the value to default value.
The case of dropping fields is the similar. App A and App B is loosely coupled, but we lost the benefit of schema evolution brought by out-of-box of the platform. Often times team end up to coordinate each other to update the two schema to avoid this 'lost in translation' case.
Approach 2:
App A has its own schema, defines the payload as json string with actually confirm to schema B and along with its schema version no, which app B can retrieve and deposit to datastore.
When app B read the data from app A, it not only read the payload but also use correct writer with right version no b.1 to deposit the data to store without losing any original data. So this approach allows two application evolve around the same schema, to avoid the lost in translation case, team A can always use the latest version of schema b.
The drawback of the approach is that we need to make sure the json payload is validated against schema b.1 and now we store data as json which lose the benefit of Avro serialization.
References:
https://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html